Every major AI model you use today — ChatGPT, Claude, Gemini, Copilot — is built on the same foundational idea: the Transformer architecture, first described in a 2017 Google Research paper titled Attention Is All You Need. Eight years later, a new paper from the same institution — also published at a flagship AI conference — is proposing that everything we think we understand about how these models are built may be missing something fundamental. The paper is called Nested Learning: The Illusion of Deep Learning Architectures, and it was presented at NeurIPS 2025 by Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, and Vahab Mirrokni of Google Research.
It is not a modest paper. It proposes a new learning paradigm, introduces a proof-of-concept architecture called Hope that outperforms standard transformers on several benchmarks, and directly addresses the single biggest unsolved problem in large language models: the fact that they cannot learn new things without forgetting old ones.
The Problem Nested Learning Is Trying to Solve
To understand why this paper matters, you first need to understand catastrophic forgetting — the technical term for something that makes current AI models fundamentally unlike human memory.
When you use Claude or ChatGPT, the model's knowledge was baked in during a training process that happened weeks or months before you ever opened the chat window. Once training ended, the model's weights were frozen. It stopped learning. Whatever it did not know at that point, it still does not know now — unless it can search the web, or unless the company has run a fresh round of training and released a new version.
This is not a design choice made for safety or simplicity. It is a technical constraint. If you try to update a neural network on new data without retraining on all the old data simultaneously, the new information overwrites the old. The model forgets. Researchers call this catastrophic forgetting, and it has been an open problem in machine learning since the 1980s.
Current workarounds are imperfect. Giving a model access to live web search helps with factual currency but does not update the model's underlying knowledge or reasoning. Retrieval-augmented generation (RAG) — where a model searches a private document store before answering — patches the symptom without curing the cause. Fine-tuning on new data typically degrades performance on previously learned tasks. There is no clean, principled solution at scale.
The human brain adapts through neuroplasticity — the capacity to change its structure in response to new experiences. Current LLMs have no equivalent. Their knowledge is confined to either the immediate context window or the static information acquired during pre-training.
— Google Research blog, November 2025
What Nested Learning Actually Proposes
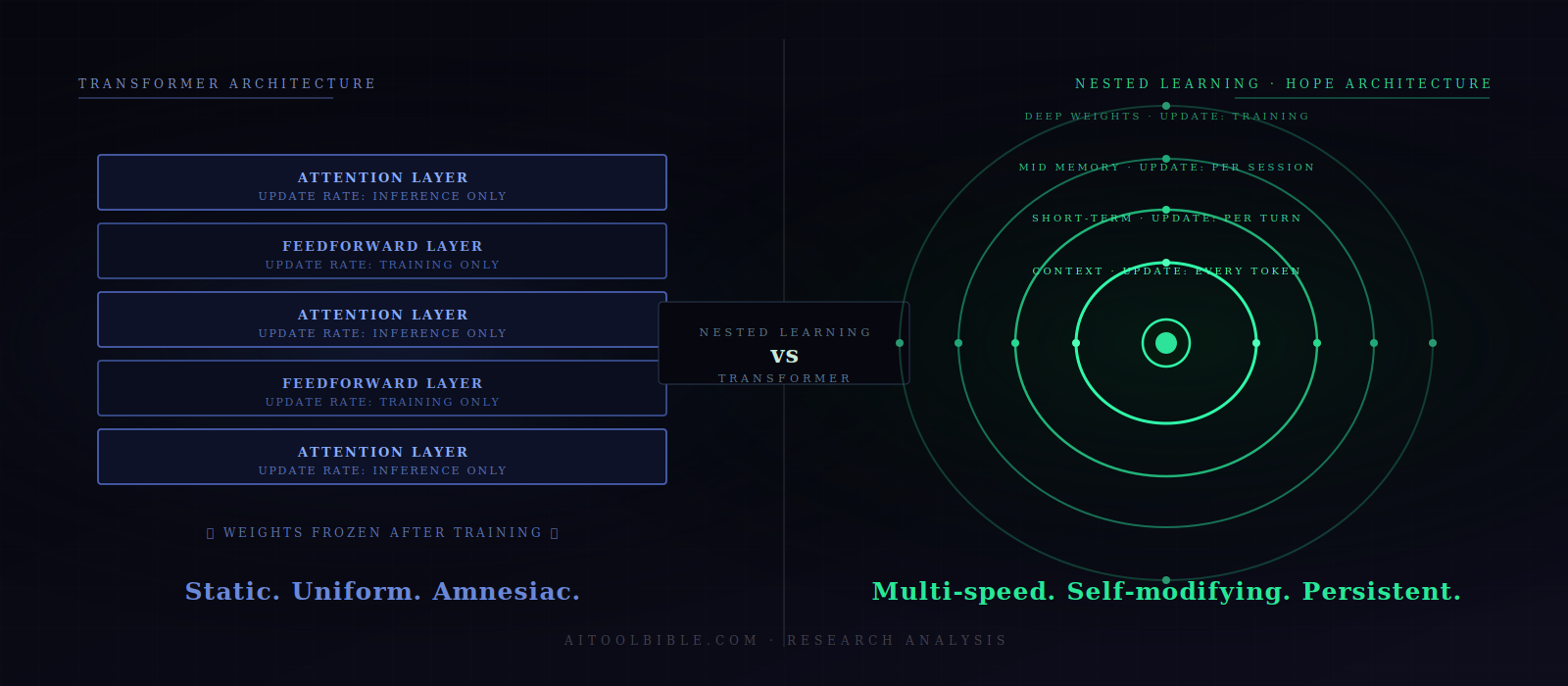
The paper's central argument is deceptively simple: the division between a neural network's architecture (its layers, attention heads, structure) and its optimisation algorithm (the training rules that update its weights) is artificial. They are not fundamentally different things — they are the same kind of process operating at different speeds.
Under the Nested Learning framework, any machine learning model can be described as a set of interconnected optimisation problems running simultaneously, each with its own "context flow" — its own stream of information it is learning from, updating at its own frequency. Some update rapidly (like attention mechanisms responding to the current input), others very slowly (like the deep weights encoding general world knowledge). Stack these levels together, and you get what the authors call a Nested Learning system.
This reframing has an immediate implication. Current deep learning methods, including transformers, work by compressing their context flows into fixed weights at training time. Everything gets baked in at one go, then frozen. Nested Learning says that if you instead allow each level of the model to update at its own appropriate frequency — some weights adjusting during every forward pass, others adjusting daily, others almost never — you can build a model that genuinely learns over time without losing what it already knows.
The analogy the authors use is brain physiology. Human memory operates at multiple timescales simultaneously: sensory processing happens in milliseconds, short-term working memory over seconds, long-term consolidation over hours and days. Nested Learning applies this same multi-frequency principle to neural networks.
The Three Contributions in Practice
The paper is not purely theoretical. It delivers three concrete contributions that flow from the Nested Learning perspective:
1. Deep Optimisers
Standard optimisers like Adam — the algorithm used to update weights during training — are recast as associative memory modules. The paper shows that replacing the standard dot-product similarity used in momentum calculations with an L2 regression objective produces more robust optimisers that are less thrown off by noisy or inconsistent data. The authors call these "deep momentum" optimisers, and they also introduce a new variant called Multi-scale Momentum Muon (M3), which shows competitive results on vision tasks (ImageNet) and training efficiency for large language models compared to AdamW, Muon, and AdaMuon.
2. Continuum Memory System
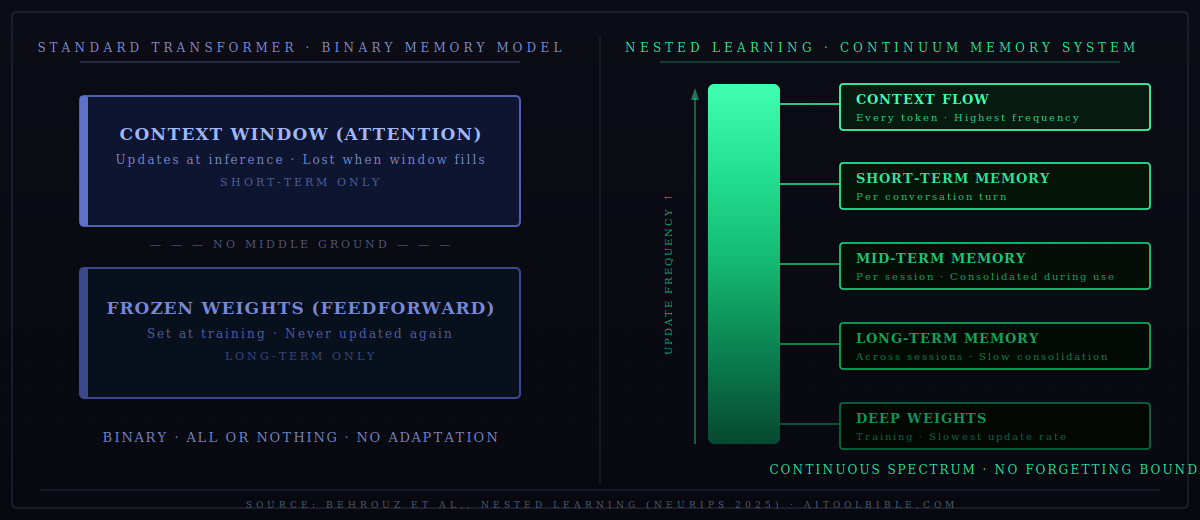
A standard transformer has a simple binary memory structure: attention holds short-term context (what is in the current window), and feedforward neural network layers hold long-term knowledge (what was learned during pre-training). The Nested Learning framework replaces this binary with a spectrum — a continuum of memory modules, each updating at a different frequency. Short-term, medium-term, and long-term memory are not two separate things but a continuous gradient. The authors call this the Continuum Memory System (CMS).
3. The Hope Architecture
Hope (Hierarchical Optimising Processing Ensemble) is the proof-of-concept architecture that combines the above ideas. It is built on top of Titans — a memory architecture Google published in early 2025 that prioritises memories based on how surprising they are (analogous to how humans pay more attention to unexpected events). Titans could only update its parameters at two levels, limiting it to first-order in-context learning. Hope adds self-modification: it can update its own update rules, creating an architecture with theoretically unbounded levels of in-context learning. It also integrates CMS blocks to handle extended context windows efficiently.
How Hope Performs Against Transformers
On language modelling benchmarks tested at 340M, 760M, and 1.3B parameter scales, Hope showed lower perplexity (a measure of prediction accuracy — lower is better) and higher accuracy on common-sense reasoning tasks compared to standard transformers, Titans, Samba, and Mamba2.
The most striking results came from long-context tasks. In Needle-in-a-Haystack (NIAH) evaluations — tests where a model must retrieve a specific piece of information buried in a very long text — Hope and Titans consistently outperformed TTT and Mamba2 across three difficulty levels (pass-key, number, and word variants). This is directly relevant to practical AI usage: it measures exactly the kind of memory performance that determines how well a model handles long documents, long conversations, or tasks requiring accurate recall from earlier in a session.
On continual learning tasks (class-incremental learning across multiple datasets), Hope significantly outperformed baseline continual learning methods and standard in-context learning approaches.
What This Means for Current Transformer-Based AI
The models in your AI tools today — GPT-5, Claude Sonnet, Gemini — are all transformer-based. Nested Learning does not immediately change any of that. But it does reframe what transformers actually are and what their limits fundamentally are.
Under the Nested Learning lens, well-known transformer architectures turn out to be expressible as "linear layers with different update frequencies." The attention mechanism is a form of associative memory that updates at inference time; the feedforward layers are a form of associative memory that updates (only) at training time. The paper is not saying transformers are wrong — it is saying they occupy just one point in a much larger design space that we have barely begun to explore.
For users of current AI tools, the near-term implications are limited. GPT-5, Claude, and Gemini will not suddenly gain new capabilities because of this paper. What the paper does is provide a principled framework for the next generation of architectures — the models that research teams are building now, or will build in the next two to three years.
The medium-term implications are more significant:
- AI that updates on the fly: Models built on Nested Learning principles could integrate new information — a document you share, an update in your field, a change in your preferences — directly into their weights during your session, rather than holding it only in a context window that gets truncated.
- Persistent memory across sessions: Instead of the current workaround of saving memories as text in a system prompt, a Nested Learning model could consolidate knowledge at the weight level, making recall more reliable and less dependent on context length management.
- Fewer re-training cycles for developers: AI products that need to stay current — customer service bots, legal research tools, medical references — could update continuously on new data rather than requiring expensive periodic re-training runs.
- Better long-document performance: The CMS architecture directly addresses the degradation that current models show when handling very long context windows. Tools that process lengthy contracts, research papers, or codebases would benefit materially.
Nested Learning offers a path toward smarter, more efficient models — not just bigger ones. It's a bet on architectural elegance, not just scale.
Will This Change How You Interact With AI?
In the short term: no. In the medium term: potentially yes, in specific and practical ways.
The most visible change for everyday users, if Nested Learning principles are adopted in production models, would be around memory. The current experience of telling an AI assistant something important and then watching it forget it the moment a new session starts — or worse, within a long session as context fills up — is a direct consequence of the architecture limitation this paper addresses. A model with a Continuum Memory System would not just remember longer; it would remember differently, consolidating important information into persistent weights rather than keeping it alive only as text in a prompt.
The interaction shift would be subtle but meaningful. Conversations would carry more genuine continuity. An AI assistant that has worked with you over weeks would actually know things about your preferences, your projects, and your working style in a way that does not have to be re-explained each session. That is not possible with current architectures without engineering hacks. It is the natural output of a properly implemented Nested Learning system.
For developers building on AI APIs, the implications are more immediate. Models that can update during inference — rather than requiring full fine-tuning cycles — would change how domain-specific AI products are built and maintained.
Will It Cost More, Less, or Make No Difference to Credit Usage?
This is not something the paper directly addresses — it is a research paper, not a product announcement. But the question is worth thinking through carefully, because it affects anyone paying for API access or using credit-based AI tools.
There are two competing forces at play:
Reason costs might fall: The Continuum Memory System is designed to be more computationally efficient than transformer attention for long sequences. Standard transformer attention scales quadratically with context length — as your conversation or document gets longer, the compute cost rises steeply. Recurrent architectures like Hope scale more linearly. For long-context tasks, this could translate to lower costs per token than current transformer-based models require for the same quality of output.
Reason costs might rise (initially): Self-modifying architectures that update weights during inference are doing more computation per forward pass than a static transformer. The overhead of running multiple memory levels at different update frequencies adds real cost. At the current proof-of-concept stage, this is unlikely to be optimised for commercial deployment.
The honest answer for now: no change to your current bills, because current AI tools are not built on Nested Learning. If and when models built on these principles reach production, pricing will depend on how the compute overhead is optimised — but the long-context efficiency gains are a genuine reason to expect costs for extended tasks to be lower than equivalent transformer usage, not higher.
What is already happening, separately from this paper, is that LLM API prices have dropped roughly 80% across the industry between early 2025 and early 2026. That trend is driven by hardware improvements and competition, and it will continue regardless of which architecture wins the next generation.
The Honest Limitations
Hope is a proof-of-concept tested at up to 1.3 billion parameters. The largest transformer models in production — GPT-5, Claude Opus, Gemini Ultra — operate at scales many times larger. Whether the Nested Learning paradigm holds its advantages at production scale is an open question the paper does not and cannot answer.
Roboticist and AI researcher Chris Paxton, writing about the paper on his Substack It Can Think, offered a grounded assessment: "These seem fairly far from use on anything more than toy tasks — and inference with transformers continues to improve, in part because they scale extremely well. Titans and HOPE won't be replacing GPT next year or anything."
That is a fair read. The paper also currently sits at the proof-of-concept stage with no public code release confirmed for the full Hope implementation at the time of writing. Peer review comments on OpenReview indicate the theoretical framework is well-received, but independent replication of results is still limited.
It is also worth noting that transformer architectures have shown a consistent ability to absorb and accommodate new research — mixture of experts, sparse attention, flash attention, and other innovations have all extended transformer capability beyond what early critics expected. The assumption that transformers will simply stop scaling is not settled.
What It Means in Plain Terms
Nested Learning is the most structurally interesting AI research paper since the original Titans work in early 2025, and arguably since the Mamba state-space model work before that. It does not improve any AI tool you are using today. What it does is provide a principled answer to a question that the transformer architecture has always left unanswered: how do you build a model that genuinely learns over time, without destroying what it already knows?
The paper argues — convincingly, with empirical results to support it — that the answer is to stop treating the model's structure and its training rules as separate things, and instead design systems where different components update at different frequencies, like the human brain. The Hope architecture is an early demonstration that this is not just theoretically appealing but practically superior to current approaches on the tasks where transformers are weakest: long context, continual learning, and knowledge incorporation.
For people using AI tools today, the practical takeaways are:
- The "knowledge cutoff" problem — AI models that don't know about recent events — is not a permanent feature of AI. It is an artefact of the current architecture. Nested Learning offers a genuine path to models that update continuously.
- The persistent memory problem — AI assistants that forget you between sessions — is addressable at the architectural level, not just with text-based memory hacks. Expect to see this improve over the next two to three years as these ideas move from research into product.
- Your current AI credit costs will not change because of this paper. If production models adopt these principles, long-context tasks may become cheaper relative to equivalent transformer performance, but the timeline is years, not months.
- The research came from Google Research. Google's AI products — Gemini, NotebookLM, and whatever comes next — are the most likely first adopters if these ideas move to production. Worth watching.
The paper is available on arXiv (2512.24695) and the NeurIPS 2025 proceedings. The Google Research blog post — written by two of the authors — is the most accessible introduction: research.google/blog/introducing-nested-learning.